مقدمه
امروزه، تحلیل جریان سیالات محاسباتی (Computational Fluid Dynamics یا CFD) تبدیل به یکی از اجزای کلیدی در طراحی محصولات، بهینهسازی فرآیندها و کاهش هزینههای توسعه شده است. نرمافزار ANSYS Fluent با توانایی مدلسازی انواع پدیدههای جریان سیال ، حرارت و توربولانس، به عنوان یکی از محبوبترین ابزارهای CFD شناخته میشود. ولی با افزایش پیچیدگی هندسهها و مدلهای فیزیکی ، نیاز به منابع محاسباتی بزرگ برای تسریع فرایند شبیهسازی احساس میشود .

چرا ابررایانه ؟
ابر رایانهها متشکل از صد ها تا هزاران پردازنده موازی هستند که میتوانند حجم بالایی از محاسبات موازی را در زمان کوتاه انجام دهند :
- قابلیت مقیاس پذیری: امکان اجرای شبیهسازی روی ده ها تا هزاران هسته پردازشی به صورت همزمان
- سعت بخشیدن به الگوریتم ها: استفاده از GPU و شتاب دهندههای سختافزاری، جهت پردازش ماتریس های بزرگ
- افزایش دقت: تخصیص حافظه ی بیشتر برای مشبندی های ریزتر و مدل های چند فازی پیچیده
- کاهش هزینه زمانی: از چند روز به چند ساعت، یا حتی دقیقه برای پروژه های بزرگ
معماری ابررایانه برای CFD
- گرههای پردازشی ( Compute Nodes ) : هر گره شامل چندین CPU چند هستهای یا GPU است.
- شبکه پر سرعت ( Interconnect ): فناوریهای اینفینی بند (InfiniBand) یا اترنت با تاخیر کم برای تبادل داده سریع بین گرهها.
- سیستم فایل توزیع شده (Parallel File System) : مانند Lustre یا GPFS برای خواندن / نوشتن سریع داده های مش و نتایج.
گام به گام پیاده سازی ANSYS Fluent روی ابررایانه
۱. آماده سازی محیط نرم افزاری
- نصب ANSYS Fluent با لایسنس شبکهای روی گرههای مستقر
- راهاندازی MPI (مانند Intel MPI یا OpenMPI) جهت ارتباط بین فرآیندها
- تنظیم متغیرهای محیطی:
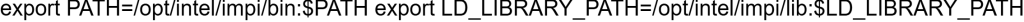
۲. پیکربندی فایل Case و Data
- تنظیم پارامترهای اجرای موازی در فایل journal یا case.jou:
fluent 3d -g -t$(NPROCS) -mpi=intel -i case.jou - تعریف تعداد هسته (NPROCS) بر اساس تعداد هستههای در دسترس و بار هر هسته
۳. راهاندازی شبیهسازی موازی
- اجرای اسکریپت شبیهسازی با SLURM یا TORQUE
#!/bin/bash #SBATCH --nodes=4 #SBATCH --ntasks-per-node=64 #SBATCH --time=12:00:00 module load ansys module load intel-mpi srun fluent 3d -g -t256 -mpi=intel -i case.jou - نظارت بر مصرف منابع با
htop،nvidia-smiو ابزارهای مدیریت خوشه

۴. بهینهسازی عملکرد
| روش بهینهسازی | توضیح |
|---|---|
| NUMA Binding | هم ترازی حافظه و CPU برای کاهش تاخیر دسترسی |
| MPI+OpenMP Hybrid | تقسیم کار میان فرایندها و تردها برای حداکثر بهرهوری |
| پروفایلینگ | استفاده از Intel VTune یا GNU gprof برای شناسایی گلوگاهها |
| GPU Offloading | انتقال بخشهای مناسب کد به GPU برای افزایش سرعت |

مطالعات موردی (Case Studies)
مطالعه موردی ۱ : بهینهسازی جریان اطراف بدنه خودرو
- مشخصات: هندسه پیچیده خودرو، مشبندی ۵۰ میلیون سلول
- تنظیمات محاسباتی: ۵۱۲ هسته CPU با شبکه InfiniBand 100Gbps
- نتیجه: کاهش زمان شبیه سازی از ۱۲۰ ساعت به ۲۸ ساعت (۷۶% صرفهجویی)
مطالعه موردی ۲ : تحلیل توربولانس جریان هواپیما
- مشخصات : پروفیل بال با جزئیات سطحی بالا، مش ریز ۱۲۰ میلیون سلول
- تنظیمات محاسباتی : ۲۵۶ هسته CPU + 4 کارت NVIDIA A100
- نتیجه : رسیدن به توربولانس دقیق با انحراف فشار کمتر از ۱٪، کاهش زمان از ۱۰ روز به ۲ روز
مطالعه موردی ۳ : شبیهسازی انتقال حرارت چندفازی
- مشخصات : جریان چندفازی با تبخیر/تقویت حرارتی
- تنظیمات محاسباتی : خوشه GPU مبتنی بر CUDA
- نتیجه : افزایش سرعت محاسبات ۳.۵ برابر نسبت به حالت فقط CPU
نکات کلیدی و چالشها
- پیکربندی MPI : انتخاب نسخه و تنظیمات صحیح برای کمترین تاخیر
- مدیریت حافظه : اطمینان از رسیدن به بالاتری نرخ انتقال داده
- تطبیق مشبندی : ایجاد تعادل بین دقت و حجم محاسبات
- هزینه و لایسنس : محاسبه هزینه واقعی استفاده از ابررایانه و لایسنس نرمافزار
بهترین روشها (Best Practices)
- آزمون مقیاسپذیری : اجرای شبیهسازیهای کوچک برای یافتن نقطه بهینه تعداد هستهها
- پایش مستمر : مانیتورینگ لحظهای مصرف CPU ، حافظه و شبکه
- بهروزرسانی منظم: استفاده از نسخههای جدید Fluent و درایورهای GPU
- سندبندی و مستندسازی: ثبت تنظیمات ، نتایج و یافتهها برای تکرارپذیری
جمعبندی و نتیجهگیری
اجرای ANSYS Fluent روی ابر رایانه با فراهم آوردن منابع عظیم محاسباتی، میتواند سرعت و دقت پروژههای CFD را چندین برابر کند. با رعایت مراحل پیادهسازی ، بهینهسازی تنظیمات MPI/GPU و استفاده از بهترین روش ها، مهندسان و پژوهشگران قادر خواهند بود پیچیدهترین مسائل جریان سیال را در زمان و هزینه کمتر حل کنند.
برای دریافت مشاوره تخصصی و خدمات پیادهسازی شبیهسازی CFD روی ابررایانه، با تیم فنی ما در ارتباط باشید.
کلمات کلیدی: ابررایانه، ANSYS Fluent، CFD، موازیسازی، GPU Offloading، NUMA Binding، InfiniBand، SLURM، پروفایلینگ، ابررایانه انسیس، انسیس فلوئنت، ابررایانه فلوئنت، ابر رایانه انسیس، ابر رایانه فلوئنت
مقاله مادر:











